Scraping thousands of temporary (disposable) phone numbers
This is the first article of a series about temporary phone numbers (update: 2nd article has been published).Temporary phone numbers are virtual numbers used for a short period, allowing users to receive calls and messages without revealing their personal number. They are commonly exploited by fraudsters because they provide anonymity and can be quickly discarded, making it harder for law enforcement to track their activities. Fraudsters use these numbers to carry out scams, create fake accounts, and other illicit activities while evading detection.
If you are interested in a list of temporary phone numbers, you can access a list of thousands of temporary phone numbers:
Downloading a list of temporary phone numbers
There exists several websites that provide free temporary phone number services. In our case, we focus on https://sms24.me/en.The website provides temporary phone numbers located in 53 countries.
 The first step is to obtain the list of all the countries so that we can iterate on them later with our scraper.This first step is manual and done from the Chrome devtools. We simply execute
The first step is to obtain the list of all the countries so that we can iterate on them later with our scraper.This first step is manual and done from the Chrome devtools. We simply execute Array.from(document.querySelectorAll('.callout')).map(aElt => aElt.href.split('/').pop()) which returns an array that contains all the ISO code of the countries with temporary phone numbers available.We store this into an array to reuse it in our scraper:
const countryIsoCodes = ['au', 'at', 'bd', 'be', 'br', 'bg', 'ca', 'cl', 'cn', 'co', 'hr', 'cz', 'dk', 'ee', 'fi', 'fr', 'ge', 'de', 'hk', 'in', 'id', 'il', 'it', 'jp', 'jo', 'kz', 'lv', 'lt', 'my', 'mx', 'mm', 'nl', 'nz', 'ng', 'no', 'ph', 'pl', 'pt', 'pr', 'ro', 'ru', 'rs', 'za', 'kr', 'es', 'se', 'ch', 'th', 'ua', 'gb', 'us', 'uz', 'vn'];// downloadListPhoneNumbers.js
const http = require('https');
const cheerio = require('cheerio');
const fs = require('fs');
const DEFAULT_HEADERS = {
"accept": "text/plain, */*; q=0.01",
"accept-language": "fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7",
"content-type": "application/x-www-form-urlencoded; charset=UTF-8",
'pragma': 'no-cache',
'cache-control': 'no-cache',
"sec-ch-ua": "\"Chromium\";v=\"92\", \" Not A;Brand\";v=\"99\", \"Google Chrome\";v=\"92\"",
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'cors',
'sec-fetch-dest': 'empty',
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36",
}
async function getURL(url, headers) {
return new Promise((resolve, reject) => {
const request = http.request(url, { headers: headers }, (res) => {
let data = ""
res.on("data", d => {
data += d
})
res.on("end", () => {
resolve(data);
})
res.on("error", (err) => {
reject(err);
})
})
request.on('error', (err) => {
reject(err);
});
request.end();
})
};
(async () => {
const countryIsoCodes = ['au', 'at', 'bd', 'be', 'br', 'bg', 'ca', 'cl', 'cn', 'co', 'hr', 'cz', 'dk', 'ee', 'fi', 'fr', 'ge', 'de', 'hk', 'in', 'id', 'il', 'it', 'jp', 'jo', 'kz', 'lv', 'lt', 'my', 'mx', 'mm', 'nl', 'nz', 'ng', 'no', 'ph', 'pl', 'pt', 'pr', 'ro', 'ru', 'rs', 'za', 'kr', 'es', 'se', 'ch', 'th', 'ua', 'gb', 'us', 'uz', 'vn'];
// Code of the scraper here ...
})();- Extract the number of pages to scrape for the country (at the bottom of the screenshot below),
- Iterate over all the pages to extract the phone numbers.
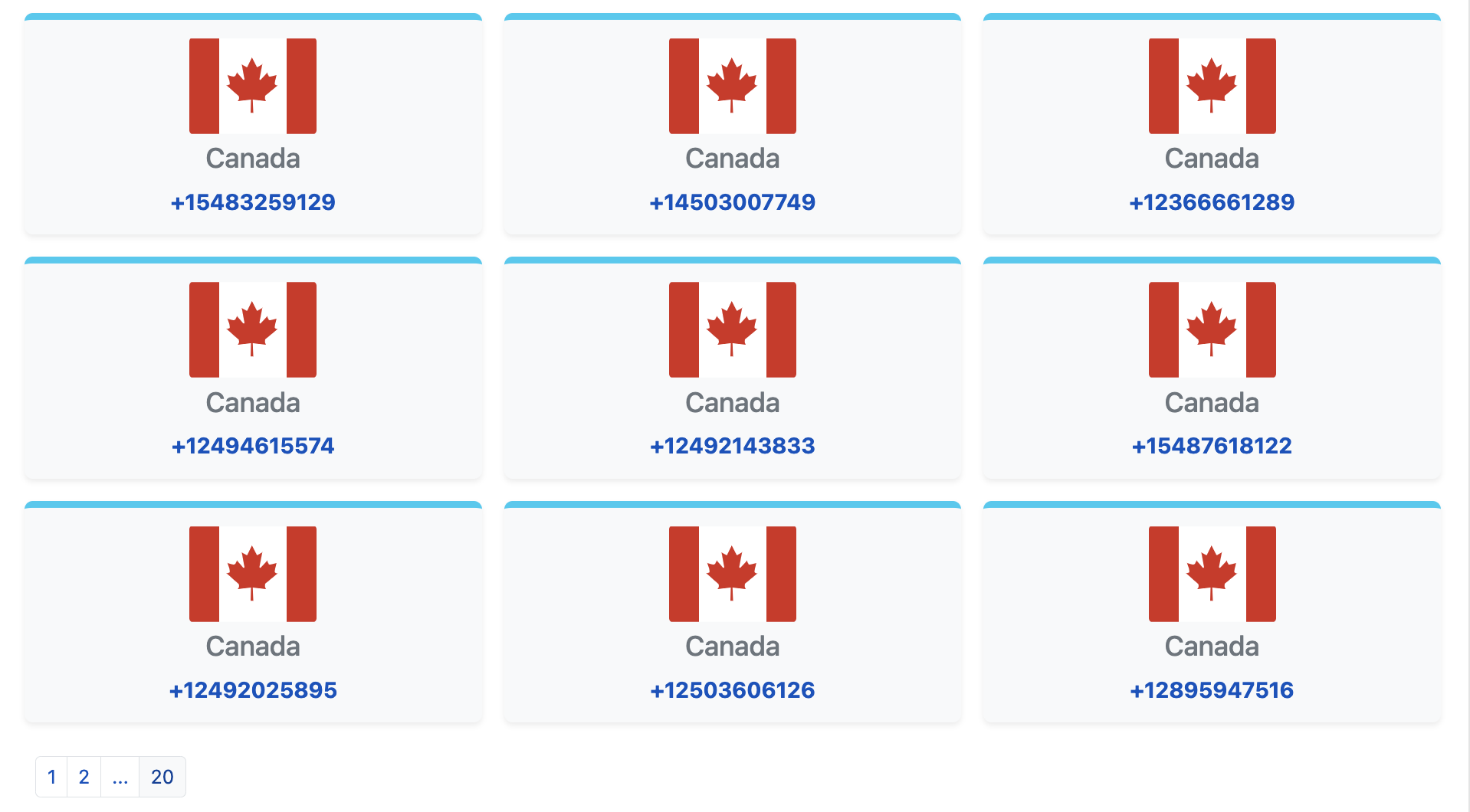
const phoneNumbers = [];
for (let country of countryIsoCodes) {
console.log(`Start scraping phone numbers for country = ${country}`);
const countryBaseUrl = `https://sms24.me/en/countries/${country}`;
const countryPageContent = await getURL(`${countryBaseUrl}/1`, DEFAULT_HEADERS);
const $ = cheerio.load(countryPageContent);
paginationLinks = $('.pagination li');
const numPagesCountry = parseInt($(Array.from(paginationLinks).pop()).text());
console.log(`Number of pages to scrape: ${numPagesCountry}`);
links = $('a.callout');
$(links).each((i, link) => {
phoneNumbers.push($(link).attr('href').split('/').pop());
});
for (let indexPage = 2; indexPage <= numPagesCountry; indexPage++) {
const countryPageContent = await getURL(`${countryBaseUrl}/${indexPage}`, DEFAULT_HEADERS);
const $ = cheerio.load(countryPageContent);
links = $('a.callout');
$(links).each((i, link) => {
phoneNumbers.push($(link).attr('href').split('/').pop());
});
}
}Finally, we store the list of temporary phone numbers in a JSON file to reuse it in the next step of our scrapers where we will download the content of the message:
fs.writeFileSync('./phonenumbers.json', JSON.stringify(phoneNumbers));Downloading messages received by the temporary phone numbers
The second step of our scraper is to download all the messages/SMS that have been received by the temporary phone numbers we identified in the previous step. We add the code into a second JS file to better differentiate each step. The file has a similar structure as before:
// downloadMessagesPhoneNumber.js
const http = require('https');
const cheerio = require('cheerio');
const fs = require('fs');
const phoneNumbers = require('./phonenumbers.json');
const DEFAULT_HEADERS = {
"accept": "text/plain, */*; q=0.01",
// ...
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36",
}
async function getURL(url, headers) {
// ...
};
(async () => {
// code of the 2nd scraper here
})();We iterate over all the phone numbers, and for each of them, we:
- Extract the number of pages to scrape for the phone number;
- Iterate over all the pages to extract the messages (content and sender).
const messages = [];
for (let phoneNumber of phoneNumbers) {
console.log(`Start scraping messages for number = ${phoneNumber}`);
const phoneBaseUrl = `https://sms24.me/en/numbers/${phoneNumber}`;
const phoneNumberPageContent = await getURL(`${phoneBaseUrl}/1`, DEFAULT_HEADERS);
const $ = cheerio.load(phoneNumberPageContent);
paginationLinks = $('.pagination li');
const numPagesMessagesForPhoneNumber = parseInt($(Array.from(paginationLinks).pop()).text());
console.log(`Number of pages to scrape: ${numPagesMessagesForPhoneNumber}`);
const messagesElts = $('dd');
$(messagesElts).each((i, msgElt) => {
const sender = $(msgElt).find('a').text().split('From: ').pop();
const message = $(msgElt).find('span').text();
messages.push({
sender: sender,
message: message
})
});
for (let indexPage = 2; indexPage <= numPagesMessagesForPhoneNumber; indexPage++) {
const phoneNumberPageContent = await getURL(`${phoneBaseUrl}/${indexPage}`, DEFAULT_HEADERS);
const $ = cheerio.load(phoneNumberPageContent);
const messagesElts = $('dd');
$(messagesElts).each((i, msgElt) => {
const sender = $(msgElt).find('a').text().split('From: ').pop();
const message = $(msgElt).find('span').text();
messages.push({
sender: sender,
message: message
})
});
}
}Finally, we save the content of the messages into a JSON file for further analysis (in the next article): fs.writeFileSync('./messages.json', JSON.stringify(messages));
In total, our scraper enabled us to collect 5,340 temporary phone numbers and 393,310 messages. In the next article of this series (update: 2nd article has been published) we will analyze the content and the senders of the messages received by these temporary phone numbers to study the services that are targeted by temporary numbers.
Other recommended articles
Inside the IPIDEA residential proxy network disrupted by Google
This article provides an overview of the IPIDEA residential proxy network and how it was disrupted by Google.
Privacy leak: detecting anti-canvas fingerprinting browser extensions
In this article, we present 2 approaches that can be used to detect anti-canvas fingerprinting countermeasures and we discuss the potential consequences in terms of privacy for their users.
Fraud detection: how to detect if a user lied about its OS and infer its real OS?
In this article, we explain how we explain how you can detect that a user lied about the real nature of its OS by modifying its user agent. We provide different techniques that enable you to retrieve the real nature of the OS using JavaScript APIs such as WebGL and getHighEntropyValues.